This morning I shut off the Soekris Engineering net4801 that has served as our home firewall / PPP termination box for just over 18½ years.
Front view of a Soekris net4801. Clothes peg for scale.Inside of a Soekris net4801.
In truth this has been long overdue. Like, at least 10 years overdue. It has been struggling to cope with even our paltry ~60Mbps VDSL (what UK calls Fibre to the Cabinet). But I am very lazy, and change is work.
In theory we can get fibre from Openreach to approach 1Gbit/s down, and I should sort that out, but see above about me being really very lazy. The poor old Soekris would certainly not be viable then.
I’ve replaced it with a PC Engines APU2 (the apu2e2 model). Much like the Soekris it’s a fanless single board x86 computer with coreboot firmware so it’s manageable from the BIOS over serial.
An apu2e2 single board computer, image copyright PC Engines GmbH
Rear view of an APU2 case1d2redu, image copyright PC Engines GmbH
Front view of an APU2 case1d2redu, image copyright PC Engines GmbH
An APU2 case1d2redu, top and bottom halves separated, image copyright PC Engines GmbH
The Soekris ran Debian and so does the APU2. Installing it over PXE was completely straightforward on the APU2; a bit simpler than it was with the net4801 back in 2005! If you have just one and it’s right there in the same building then it’s probably quicker to just boot the Debian installer off of USB though. I may be lazy but once I do get going I’m also pointlessly bloody-minded.
Anyway, completely stock Debian works fine, though obviously it has no display whatsoever — all non-Ethernet-based interaction would have to be done over serial. By default that runs at 115200 baud (8n1).
This is not “home server” material. Like the Soekris even in 2005 it’s weak and it’s expensive for what it is. It’s meant to be an appliance. I think I was right with the Soekris’s endurance, beyond even sensible limits, and I hope I will be right about the APU2.
The Soekris is still using its original 512M CompactFlash card from 2005 by the way. Although admittedly I did go to some effort to make it run on a read-only filesystem, only flipped to read-write for upgrades.
I haven’t really been taking good care of myself which is highly inadvisable as someone with diabetes, but last week I had an extremely high blood pressure reading and so this cannot go on. At the same time I had a very high blood glucose reading although that wasn’t a surprise to me as I’ve long found it difficult to control this.
I have actually been taking my diet and level of activity half seriously and as a result I am currently at my lowest weight in over 25 years, though still at the lower end of “obese” by BMI standards. To put that into some context, in 2006 when first diagnosed with diabetes I was almost 140kg.
Anyway since my weight while not ideal is better than it’s ever been, the high blood pressure was even more of a worry. I was concerned that my kidneys might have packed up or something. Happily the result of yesterday’s bloods had my GP saying that my kidney and liver function were “perfect” (his words), which is very relieving but does leave me wondering what else I can do.
For now the GP has prescribed me some pills for blood pressure and told me to come back in a month for another blood test and blood pressure check, so it seems like he isn’t overly concerned. With the blood pressure as high as it is I was seriously wondering if he was going to call me with the results and say “go to hospital now”.
Clearly even though I thought I was doing okay with the weight loss I am going to have to step things up a bit.
Also I am hopelessly addicted to (sugar free) fizzy drinks but I’m going to have to do something about this. Although there’s no proven link to high blood pressure, it is a bit more likely that the artificial sweeteners are going to be playing havoc with my blood sugar levels and appetite.
My habit was at the ridiculous level of over 2 litres per day but since last week’s shock I’ve started by instituting a policy of one full pint of water between any fizzy drink. Small steps but I don’t feel like I can do cold turkey.
What I have found after sticking to this policy for the last 9 days is that I often can’t physically ingest any more liquid so I don’t reach for the fizzy drink, and that it really does seem to have reduced my appetite as well. Today I had my first fizzy drink of the day with dinner, whereas before I might have had 2 litres already by that time. At the moment I’m at around 500ml a day. I hope I can keep to something like that.
The caffeine withdrawal is not pleasant. I don’t think it is a good idea to try to find another caffeine source until my blood pressure is under control. By then I might not feel the need.
If I don’t get the blood pressure under control then my near future will feature a stroke or heart attack. If I don’t get the blood sugar under control then my near future will include insulin injections.
The recent security update of the GRUB bootloader did not want to install on my fileserver at home:
$ sudo apt dist-upgrade
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
The following packages will be upgraded:
grub-common grub-pc grub-pc-bin grub2-common
4 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Need to get 4,067 kB of archives.
After this operation, 72.7 kB of additional disk space will be used.
Do you want to continue? [Y/n]
…
Setting up grub-pc (2.02+dfsg1-20+deb10u4) ...
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
$ sudo apt dist-upgrade
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
The following packages will be upgraded:
grub-common grub-pc grub-pc-bin grub2-common
4 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Need to get 4,067 kB of archives.
After this operation, 72.7 kB of additional disk space will be used.
Do you want to continue? [Y/n]
…
Setting up grub-pc (2.02+dfsg1-20+deb10u4) ...
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Installing for i386-pc platform.
grub-install: warning: your core.img is unusually large. It won't fit in the embedding area.
grub-install: error: embedding is not possible, but this is required for RAID and LVM install.
Four identical error messages, because this server has four drives upon which the operating system is installed, and I’d decided to do a four way RAID-1 of a small first partition to make up /boot. This error is coming from grub-install.
This system came to life in 2006, so it’s 15 years old. It’s always been Debian stable, so right now it runs Debian buster and during those 15 years it’s been transplanted into several different iterations of hardware.
Choices were made in 2006 that were reasonable for 2006, but it’s not 2006 now. Some of these choices are now causing problems.
Aside: four way RAID-1 might seem excessive, but we’re only talking about the small /boot partition. Back in 2006 I chose a ~256M one so if I did the minimal thing of only having a RAID-1 pair I’d have 2x 256M spare on the two other drives, which isn’t very useful. I’d honestly rather have all four system drives with the same partition table and there’s hardly ever writes to /boot anyway.
Here’s what the identical partition tables of the drives /dev/sd[abcd] look like:
$ sudo fdisk -u -l /dev/sda
Disk /dev/sda: 298.1 GiB, 320069031424 bytes, 625134827 sectors
Disk model: ST3320620AS
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x00000000
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 63 514079 514017 251M fd Linux raid autodetect
/dev/sda2 514080 6393869 5879790 2.8G fd Linux raid autodetect
/dev/sda3 6393870 625121279 618727410 295G fd Linux raid autodetect
$ sudo fdisk -u -l /dev/sda
Disk /dev/sda: 298.1 GiB, 320069031424 bytes, 625134827 sectors
Disk model: ST3320620AS
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x00000000
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 63 514079 514017 251M fd Linux raid autodetect
/dev/sda2 514080 6393869 5879790 2.8G fd Linux raid autodetect
/dev/sda3 6393870 625121279 618727410 295G fd Linux raid autodetect
Note that the first partition starts at sector 63, 32,256 bytes into the disk. Modern partition tools tend to start partitions at sector 2,048 (1,024KiB in), but this was acceptable in 2006 for me and worked up until a few days ago.
Those four partitions /dev/sd[abcd]1 make up an mdadm RAID-1 with metadata version 0.90. This was purposefully chosen because at the time of install GRUB did not have RAID support. This metadata version lives at the end of the member device so anything that just reads the device can pretend it’s an ext2 filesystem. That’s what people did many years ago to boot off of software RAID.
The last successful update of grub-pc seems to have been done on 7 February 2021:
$ ls -la /boot/grub/i386-pc/core.img
-rw-r--r-- 1 root root 31082 Feb 7 17:19 /boot/grub/i386-pc/core.img
$ ls -la /boot/grub/i386-pc/core.img
-rw-r--r-- 1 root root 31082 Feb 7 17:19 /boot/grub/i386-pc/core.img
I’ve got 62 sectors available for the core.img so that’s 31,744 bytes – just 662 bytes more than what is required.
The update of grub-pc appears to be detecting that my /boot partition is on a software RAID and is now including MD RAID support even though I don’t strictly require it. This makes the core.img larger than the space I have available for it.
I don’t think it is great that such a major change has been introduced as a security update, and it doesn’t seem like there is any easy way to tell it not to include the MD RAID support, but I’m sure everyone is doing their best here and it’s more important to get the security update out.
Option #1 is okay short term, especially if you don’t use Secure Boot as that’s what the security update was about.
Option #2 doesn’t seem that feasible as I can’t find a way to influence how Debian’s upgrade process calls grub-install. I don’t want that to become a manual process.
Option #3 seems like the easiest thing to do, as shaving ~1MiB off the size of my /boot isn’t going to cause me any issues.
At this point I would also recommend doing a wipefs -a on each of the partitions in order to remove the MD superblocks. I didn’t and it caused me a slight problem later as we shall see.
Delete and recreate first partition on each drive ^
I chose to use parted, but should be doable with fdisk or sfdisk or whatever you prefer.
I know from the fdisk output way above that the new partition needs to start at sector 2048 and end at sector 514,079.
$ sudo parted /dev/sda
GNU Parted 3.2
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) unit s
(parted) rm 1
(parted) mkpart primary ext4 2048 514079s
(parted) set 1 raid on
(parted) set 1 boot on
(parted) p
Model: ATA ST3320620AS (scsi)
Disk /dev/sda: 625134827s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 514079s 512032s primary ext4 boot, raid, lba
2 514080s 6393869s 5879790s primary raid
3 6393870s 625121279s 618727410s primary raid
(parted) q
Information: You may need to update /etc/fstab.
$ sudo parted /dev/sda
GNU Parted 3.2
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) unit s
(parted) rm 1
(parted) mkpart primary ext4 2048 514079s
(parted) set 1 raid on
(parted) set 1 boot on
(parted) p
Model: ATA ST3320620AS (scsi)
Disk /dev/sda: 625134827s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 514079s 512032s primary ext4 boot, raid, lba
2 514080s 6393869s 5879790s primary raid
3 6393870s 625121279s 618727410s primary raid
(parted) q
Information: You may need to update /etc/fstab.
Do that for each drive in turn. When I got to /dev/sdd, this happened:
Error: Partition(s) 1 on /dev/sdd have been written, but we have been unable to
inform the kernel of the change, probably because it/they are in use. As a result,
the old partition(s) will remain in use. You should reboot now before making further changes.
Ignore/Cancel?
Error: Partition(s) 1 on /dev/sdd have been written, but we have been unable to
inform the kernel of the change, probably because it/they are in use. As a result,
the old partition(s) will remain in use. You should reboot now before making further changes.
Ignore/Cancel?
The reason for this seems to be that something has decided that there is still a RAID signature on /dev/sdd1 and so it will try to incrementally assemble the RAID-1 automatically in the background. This is why I recommend a wipefs of each member device.
To get out of this situation without rebooting I needed to repeat my mdadm --stop /dev/md0 command and then do a wipefs -a /dev/sdd1. I was then able to partition it with parted.
My /etc/fstab didn’t need a change because it mounted by device name, i.e. /dev/md0, but if yours uses UUID or label then you’ll need to update that now, too.
You probably should reboot now to make sure it all works when you have time to fix any problems, as opposed to risking issues when you least expect it.
$ uprecords
# Uptime | System Boot up
----------------------------+---------------------------------------------------
1 392 days, 16:45:55 | Linux 4.7.0 Thu Jun 14 16:13:52 2018
2 325 days, 03:20:18 | Linux 3.16.0-0.bpo.4-amd Wed Apr 1 14:43:32 2015
-> 3 287 days, 16:03:12 | Linux 4.19.0-9-amd64 Fri May 22 12:33:27 2020 4 257 days, 07:31:42 | Linux 4.19.0-6-amd64 Sun Sep 8 05:00:38 2019
5 246 days, 14:45:10 | Linux 4.7.0 Sat Aug 6 06:27:52 2016
6 165 days, 01:24:22 | Linux 4.5.0-rc4-specialb Sat Feb 20 18:18:47 2016
7 131 days, 18:27:51 | Linux 3.16.0 Tue Sep 16 08:01:05 2014
8 89 days, 16:01:40 | Linux 4.7.0 Fri May 26 18:28:40 2017
9 85 days, 17:33:51 | Linux 4.7.0 Mon Feb 19 17:17:39 2018
10 63 days, 18:57:12 | Linux 3.16.0-0.bpo.4-amd Mon Jan 26 02:33:47 2015
----------------------------+---------------------------------------------------
1up in 37 days, 11:17:07 | at Mon Apr 12 15:53:46 2021
no1 in 105 days, 00:42:44 | at Sat Jun 19 05:19:23 2021
up 2362 days, 06:33:25 | since Tue Sep 16 08:01:05 2014
down 0 days, 14:02:09 | since Tue Sep 16 08:01:05 2014
%up 99.975 | since Tue Sep 16 08:01:05 2014
$ uprecords
# Uptime | System Boot up
----------------------------+---------------------------------------------------
1 392 days, 16:45:55 | Linux 4.7.0 Thu Jun 14 16:13:52 2018
2 325 days, 03:20:18 | Linux 3.16.0-0.bpo.4-amd Wed Apr 1 14:43:32 2015
-> 3 287 days, 16:03:12 | Linux 4.19.0-9-amd64 Fri May 22 12:33:27 2020
4 257 days, 07:31:42 | Linux 4.19.0-6-amd64 Sun Sep 8 05:00:38 2019
5 246 days, 14:45:10 | Linux 4.7.0 Sat Aug 6 06:27:52 2016
6 165 days, 01:24:22 | Linux 4.5.0-rc4-specialb Sat Feb 20 18:18:47 2016
7 131 days, 18:27:51 | Linux 3.16.0 Tue Sep 16 08:01:05 2014
8 89 days, 16:01:40 | Linux 4.7.0 Fri May 26 18:28:40 2017
9 85 days, 17:33:51 | Linux 4.7.0 Mon Feb 19 17:17:39 2018
10 63 days, 18:57:12 | Linux 3.16.0-0.bpo.4-amd Mon Jan 26 02:33:47 2015
----------------------------+---------------------------------------------------
1up in 37 days, 11:17:07 | at Mon Apr 12 15:53:46 2021
no1 in 105 days, 00:42:44 | at Sat Jun 19 05:19:23 2021
up 2362 days, 06:33:25 | since Tue Sep 16 08:01:05 2014
down 0 days, 14:02:09 | since Tue Sep 16 08:01:05 2014
%up 99.975 | since Tue Sep 16 08:01:05 2014
Just got back from having my first COVID-19 vaccination. Started queueing at 10:40, pre-screening questions at 10:50, all done by 10:53 then I poked at my phone for 15 minutes while waiting to check I wouldn’t keel over from anaphylactic shock (I didn’t).
I was first notified that I should book an appointment in the form of a text message from sender “GPSurgery” on Monday 22nd February 2021:
Dear MR SMITH,
You have been invited to book your COVID-19 vaccinations.
Please click on the link to book: https://accurx.thirdparty.nhs.uk/…
[Name of My GP Surgery]
The web site presented me with a wide variety of dates and times, the earliest being today, 3 days later, so I chose that. My booking was then confirmed by another text message, and another reminder message was sent yesterday. I assume these text messages were sent by some central service on behalf of my GP whose role was probably just submitting my details.
A very smooth process a 15 minute walk from my home, and I’m hearing the same about the rest of the country too.
Watching social media mentions from others saying they’ve had their vaccination and also looking at the demographics in the queue and waiting room with me, I’ve been struck by how many people have—like me—been called up for their vaccinations quite early unrelated to their age. I was probably in the bottom third age group in the queue and waiting area: I’m 45 and although most seemed older than me, there were plenty of people around my age and younger there.
It just goes to show how many people in the UK are relying on the NHS for the management of chronic health conditions that may not be obviously apparent to those around them. Which is why we must not let this thing that so many of us rely upon be taken away. I suspect that almost everyone reading either is in a position of relying upon the NHS or has nearest and dearest who do.
The NHS gets a lot of criticism for being a bottomless pit of expenditure that is inefficient and slow to embrace change. Yes, healthcare costs a lot of money especially with our ageing population, but per head we spend a lot less than many other countries: half what the US spends per capita or as a proportion of GDP; our care is universal and our life expectancy is slightly longer. In 2017 the Commonwealth Fund rated the NHS #1 in a comparison of 11 countries.
So the narrative that the NHS is poor value for money is not correct. We are getting a good financial deal. We don’t necessarily need to make it perform better, financially, although there will always be room for improvement. The NHS has a funding crisis because the government wants it to have a funding crisis. It is being deliberately starved of funding so that it fails.
The consequences of selling off the NHS will be that many people are excluded from care they need to stay alive or to maintain a tolerable standard of living. As we see with almost every private sector takeover of what were formerly public services, they strip the assets, run below-par services that just about scrape along, and then when there is any kind of downturn or unexpected event they fold and either beg for bailout or just leave the mess in the hands of the government. Either way, taxpayers pay more for less and make a small group of wealthy people even more wealthy.
We are such mugs here in UK that even other countries have realised that they can bid to take over our public services, provide a low standard of service at a low cost to run, charge a lot to the customer and make a hefty profit. Most of our train operating companies are owned by foreign governments.
The NHS as it is only runs as well as it does because the staff are driven to breaking point with an obscene amount of unpaid overtime and workplace stress.
If you’d like to learn some more about the state of the NHS in the form of an engaging read then I recommend Adam Kay’s book This is Going to Hurt: Secret Diaries of a Junior Doctor. It will make you laugh, it will make you cry and if you’ve a soul it will make you angry. Also it may indelibly sear the phrase “penis degloving injury” into your mind.
Do not accept the premise that the NHS is too expensive.
If the NHS does a poor job (and it sometimes does), understand that underfunding plays a big part.
Privatising any of it will not improve matters in any way, except for a very small number of already wealthy people.
Sometime in late December (2019) I noticed that when I clicked on a tag in Shotwell, the photo management software that I use, it was showing either zero or hardly any matching photos when I knew for sure that there should be many more.
(When I say “tag” in this article it’s mostly going to refer to the type of tags you generally put on an image, i.e. the tags that identify who or what is in the image, what event it is associated with, the place it was taken etc. Images can have many different kinds of tags containing all manner of metadata, but for avoidance of doubt please assume that I don’t mean any of those.)
I have Shotwell set to store the tags in the image files themselves, in the metadata. There is a standard for this called Exif. What seems to have happened is that Shotwell had removed a huge number of tags from the files themselves. At the time of discovery I had around 15,500 photos in my collection and it looked like the only way to tell what was in them would be by looking at them. Disaster.
Here follows some notes about what I found out when trying to recover from this situation, in case it si ever useful for anyone.
Shotwell still had a visible tag hierarchy, so I could for example click on the “Pets/Remy” tag, but this brought up only one photo that I took on 14 December 2019. I’ve been taking photos of Remy for years so I knew there should be many more. Here’s Remy.
I knew this must have happened fairly recently because I’d have noticed quite quickly that photos were “missing”. I had a look for a recent photo that I knew I’d tagged with a particular thing, and then looked in the backups to see when it was last modified.
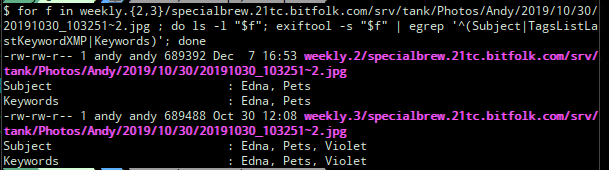
As an example I found a photo that was taken on 30 October 2019 that should have been tagged “Pets/Violet” but no longer was. It had been modified (but not by me) on 7 December 2019.
(Sorry about the text-as-images; I’m reconstructing this series of events from a Twitter thread, where things necessarily had to be posted as screenshots.)
What the above shows is that the version of the photo that existed on 30 October 2019 had the tags “Pets“, “Edna“, and “Violet” but then the version that was written on 7 December 2019 lost the “Violet” tag.
Here I used the exiftool utility to display EXIF tags from the photo files. You can do that like this:
$ exiftool -s $filename
$ exiftool -s $filename
Using egrep I limited this to the tag keys “Subject“, “Keywords“, and “TagsListLastKeywordXMP” but this was a slight mistake: “TagsListLastKeywordXMP” was actually a typo, is totally irrelevant and should be ignored.
“Subject” and “Keywords” were always identical for any photo I examined and contained the flattened list of tags. For example, in Shotwell that photo originally had the tags:
Pets/Edna
Pets/Violet
It seems that Shotwell flattens that to:
Pets
Edna
Violet
and then stores it in “Subject” and “Keywords“.
The tags with hierarchy are actually in the key “TagsList” like:
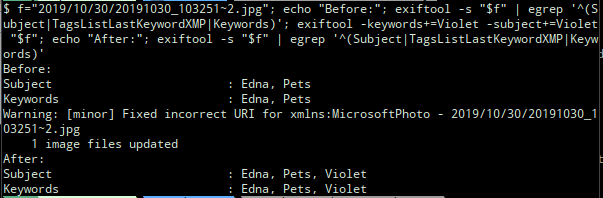
This shows that the “Violet” tag is now back in the current version of the file. After restarting Shotwell and doing a free text search for “Violet”, this photo now shows up whereas before it did not. It still did not show up when I clicked on “Pets/Violet” in the tag hierarchy however. It was then that I realised I also needed to put “Pets/Violet” into the “TagsList” key.
I ended up using a script to do this in bulk fashion, but individually I think you should be able to do this like:
It was relatively easy to work out which files had been screwed with, because thankfully I didn’t make any other photo modifications on 7 December 2019. So any photo that got modified that day was probably a candidate.
I haven’t mentioned what actually caused this problem yet. I don’t know exactly. At 16:53 on 7 December 2019 I was importing some photos into Shotwell, and I do seem to recall it crashed at some point, either while I was doing that or shortly after.
The photos from that import and all others afterwards had retained their tags correctly, but many that existed prior to that time seemed to be missing some or all tags. I have no idea why such a crash would cause Shotwell to do that but that must have been what did it.
Running this against my backups identified 3,721 files that had been modified on 7 December 2019:
$ cd weekly.2/specialbrew.21tc.bitfolk.com/srv/tank/Photos/Andy
$ find . -type f \
-newermt "2019-12-07 00:00:00" \! \
-newermt "2019-12-07 23:59:59" > ~/busted.txt
$ cd weekly.2/specialbrew.21tc.bitfolk.com/srv/tank/Photos/Andy
$ find . -type f \
-newermt "2019-12-07 00:00:00" \! \
-newermt "2019-12-07 23:59:59" > ~/busted.txt
The next thing I did was to check that each of these file paths still exist in the current photo store and in the known-good backups (weekly.3).
After transferring tags.yaml back to my home fileserver it was time to use it to stuff the tags back into the files that had lost them.
One thing to note while doing this is that if you just add a tag, it adds it even if the same tag already exists, leading to duplicates. I thought it best to first delete the tag and then add it again so that there would only be one instance of each one.
16m53s of runtime later, it had completed its work… 🙌 2020 will definitely be the year of Linux on the desktop¹.
¹ As long as you know how to manipulate EXIF tags from a programming language and have a functioning backup system and even then don’t mind losing some stuff
Unfortunately there were some things I couldn’t restore. It was at this point that I discovered that Shotwell does not ever put tags into video files (even though they do support EXIF tags…)
That means that the only record of the tags on a video file is in Shotwell’s own database, which I did not back up as I didn’t think I needed to.
I am now backing that up, but should this sort of thing happen in the future I’d need to know how to manipulate the tags for videos in Shotwell’s database.
Shotwell’s database is an SQLite file that’s normally at $HOME/.local/share/shotwell/data/photo.db. I’m fairly familiar with SQLite so I had a poke around, but couldn’t immediately see how these tags were stored. I had to ask on the Shotwell mailing list.
Here’s how Shotwell does it. There’s a table called TagTable which stores the name of each tag and a comma-separated list of every photo/video which matches it:
sqlite>.schema TagTable
CREATETABLE TagTable (id INTEGERPRIMARYKEY, name TEXT UNIQUENOTNULL, photo_id_list TEXT, time_created INTEGER);
sqlite> .schema TagTable
CREATE TABLE TagTable (id INTEGER PRIMARY KEY, name TEXT UNIQUE NOT NULL, photo_id_list TEXT, time_created INTEGER);
The photo_id_list column holds the comma-separated list. Each item in the list is of the form:
“thumb” or “video-” depending on whether the item is a photo or a video
16 hex digits, zero padded, which is the ID value from the PhotosTable or VideosTable for that item
a comma
Full example of extracting tags for the video file 2019/12/31/20191231_121604.mp4:
$ sqlite3 /home/andy/.local/share/shotwell/DATA/photo.db
SQLite version 3.22.0 2018-01-2218:45:57
Enter ".help"FOR usage hints.
sqlite>SELECT id
FROM VideoTable
WHERE filename LIKE'%20191231%';
553
sqlite>SELECT printf("%016x",553);
0000000000000229
sqlite>SELECT name
FROM TagTable
WHERE photo_id_list LIKE'%video-0000000000000229,%';
/Places
/Places/London
/Places/London/Feltham
/Pets
/Places/London/Feltham/Bedfont Lakes
/Pets/Marge
/Pets/Mandy
$ sqlite3 /home/andy/.local/share/shotwell/data/photo.db
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
sqlite> select id
from VideoTable
where filename like '%20191231%';
553
sqlite> select printf("%016x", 553);
0000000000000229
sqlite> select name
from TagTable
where photo_id_list like '%video-0000000000000229,%';
/Places
/Places/London
/Places/London/Feltham
/Pets
/Places/London/Feltham/Bedfont Lakes
/Pets/Marge
/Pets/Mandy
If that is not completely clear:
The ID for that video file is 553
553 in hexadecial is 229
Pad that to 16 digits, add “video-” at the front and “.” at the end (even the last item in the list has a comma at the end)
Search for that string in photo_id_list
If a row matches then the name column is a tag that is attached to that file
I don’t exactly know how I would have identified which videos got messed with, but at least I would have had both versions of the database to compare, and I now know how I would do the comparison.
Exif exists for the purpose of storing tags like this.
When I move my photos from one piece of software to another I want it to be able to read the tags. I don’t want to have to input them all over again. That would be unimaginably tedious.
When I moved from F-Spot to Shotwell the fact that the tags were in the files saved me countless hours of work. It just worked on import.
If there wasn’t a dedicated importer feature then it would be so much work that really the only way to do it would be to extract the tags from the database and insert them again programmatically, which is basically admitting that to change software you need to be an expert. That really isn’t how this should work.
If the only copy of my tags is in the internal database of a unique piece of cataloging software, then I have to become an expert on the internal data store of that piece of software. I don’t want to have to do that.
I’ve been forced to do that here for Shotwell because of a deficiency of Shotwell in not storing video tags in the files. But if we’re only talking about photos then I could have avoided it, and could also avoid having to be an expert on every future piece of cataloging software.
Even if I’m not moving to a different cataloging solution, lots of software understands Exif and it’s useful to be able to query those things from other software.
I regard it very much like artist, album, author, genre etc tags in the metadata of digital music and ebooks, all of which are in the files; you would not expect to have to reconstruct these out of the database of some other bit of software every time you wanted to use them elsewhere.
It was a mistake not to backup the Shotwell database though; I thought I did not need it as I thought all tags were being stored in files, and tags were the only things I cared about. As it happened, tags were not being stored in video files and tags for video files only exist in Shotwell’s database.
Having backups was obviously a lifesaver here. It took me ~3 weeks to notice.
Being able to manipulate them like a regular filesystem made things a lot more convenient, so that’s a property I will want to keep in whatever future backup arrangements I have.
I might very well switch to different photo management software now, assuming I could find any that I prefer, but all software has bugs. Whatever I switch to I would have to ensure that I knew how to extract the tags from that as well, if it doesn’t store them in the files.
I don’t want to store my photos and videos “in the cloud” but it is a shortcoming of Shotwell that I can basically only use it from my desktop at home. Its database does not support multiple or remote access. I wonder if there is some web-based thing that can just read (and cache) the tags out of the files, build dynamic galleries and allow arbitrary searches on them…
Shotwell’s database schema and its use of 16 hexadecimal digits (nibbles?) means I can only store a maximum of 18,446,744,073,709,551,615 (1.844674407×10¹⁹ -1) photos or videos of dogs. Arbitrary limits suck so much.
I’ve been a customer of LoveFiLM for something like 12 years—since before they were owned by Amazon. In their original incarnation they were great: very cheap, and titles very often arrived in exactly the order you specified, i.e. they often managed to send the thing from the very top of the list.
In 2011 they got bought by Amazon and I was initially a bit concerned, but to be honest Amazon have run it well. The single list disappeared and was replaced by three priority lists; high, normal and low, and then a list of things that haven’t yet been released. New rentals were supposed to almost always come from the high priority list (as long as you had enough titles on there) but in a completely unpredictable order. Though of course they would keep multi-disc box sets together, and send lower-numbered seasons before later seasons.
It was inevitable I suppose due to the increasing popularity of streaming and downloads, and although I’m perfectly able to do the streaming and download thing, receiving discs by post still works for me.
I am used to receiving mockery for consuming some of my entertainment on little plastic discs that a human being has to physically transport to my residence, but LoveFiLM’s service was still cheap, the selection was very good, things could be rented as soon as they were available on disc, and the passive nature of just making a list and having the things sent to me worked well for me.
My first thought was that that was it for the disc-by-post rental model in the UK. That progress had left it behind. But very quickly people pointed me to Cinema Paradiso. After a quick look around I’ve decided to give it a try and so here are my initial thoughts.
At a casual glance the pricing is slightly worse than LoveFiLM’s. I was paying £6.99 a month for 2 discs at home, unlimited rental per month. £6.98 at Cinema Paradiso gets you 2 discs at home but only 4 rentals per month.
I went back through my LoveFiLM rental history for the last year and found there were only 2 months where I managed to rent more than 4 discs, and those times I rented 5 and 6 discs respectively. Realistically it doesn’t seem like 4 discs per month will be much of a restriction to me.
Annoyingly, Cinema Paradiso have a 2 week trial period but only if you sign up to the £9.98 subscription (6 discs a month). You’d have to remember to downgrade to the cheaper subscriptions after 2 weeks, if that’s all you wanted.
I was pleasantly surprised at how good the selection is at Cinema Paradiso. Not only did they have every title that is currently on my LoveFiLM rental list (96 titles), but they also had a few things that LoveFiLM thinks haven’t been released yet.
I’m not going to claim that my tastes are particularly niche, but there are a few foreign language films and some anime in there, and release dates range from the 70s to 2017.
It seems that new Cinema Paradiso signups need to be manually approved, and this happens only on week days between 8am and mid day. I’ve signed up on a Saturday evening so nothing will get sent out until Monday I suppose.
It’s probably not a big deal as we’re talking about the postal service here so even with LoveFiLM nothing would get posted out until Monday anyway. It is a little jarring after moving away from the behemoth that is Amazon though, and serves as a reminder that Cinema Paradiso is a much smaller company.
The search feature is okay. It provides suggestions as you type but if your title is obscure then it may not appear in the list of suggestions at all you and need to submit the search box and look through the longer list that appears.
A slight niggle is that if you have moused over any of the initial suggestions it replaces your text with that, so if your title isn’t amongst the suggestions you now have to re-type it.
I like that it shows a rating from Rotten Tomatoes as well as from their own site’s users. LoveFiLM shows IMDB ratings which I don’t trust very much, and also Amazon ratings, which I don’t trust at all for movies or TV. Seeing some of the shockingly-low Rotten Tomatoes scores for some of my LoveFiLM titles resulted in my Cinema Paradiso list shrinking to 83 titles!
It’s hard to tell for sure at this stage because I haven’t yet got my account approved and had any rentals, but it looks to me like the rental list mechanics are a bit clunky compared to LoveFiLM’s.
At LoveFiLM at the point of adding a new title you would choose which of the three “buckets” to put a rental in; high priority, normal priority, or low priority. Every title in those buckets were of equal priority to every other item in the same bucket. So, when adding a new title all you had to consider was whether it was high, medium or low.
Cinema Paradiso has a single big list of rentals. In some ways this might appeal because you can fine-tune what order you would like things in. But I would suggest that very few people want to put that much effort into ordering their list. Personally, when I add a new title I can cope with:
“I want to see this soon”
“I want to see this some time”
“I want to see this, but I’m not bothered when”
Cinema Paradiso appears to want me to say:
“Put this at the top, I want it immediately!”
“This belongs at #11, just after the 6th season of American Horror Story, but before Capitalism: A love Story“
“Just stick it at the end”
I can’t find any explanation anywhere on their site as to how the selection actually works, so the logical assumption is that they go down your list from top to bottom until they find a title that you want that they have available right now. Without the three buckets to put titles in, it seems to me then that every addition will have to involve some list management unless I either want to see that title really soon, or probably never.
I’ll have to give it a go but this mechanism seems a bit more awkward than LoveFiLM’s approach and needlessly so, because LoveFiLM’s way doesn’t make any promises about which of the titles in each bucket will come next either, nor even that it will be anything from the high priority bucket at all. Although I cannot remember a time when something has come that wasn’t from the high priority bucket.
Cinema Paradiso does let you have more than one list, and you can divide your disc allocation between lists, but I don’t think I could emulate the high/normal/low with that. Having a 2 disc allocation I’d always be getting one disc from the “high” list and one disc from the “normal” priority, which isn’t how I’d want that to work.
I did not know when I signed up that there was a referral scheme which is a shame because I do know some people already using Cinema Paradiso. If you’re going to sign up then please use my referral link. I will get a ⅙ reduction in rental fees for each person that does.
Yesterday afternoon I noticed that my music player, Banshee, had not been scrobbling to my Last.fm for a few weeks. Last.fm seem to be in the middle of reorganising their site but that shouldn’t affect their API (at least not for scrobbling). However, it seems that it has upset Banshee so no more scrobbling for me.
Banshee has a number of deficiencies but there’s a few things about it that I really do like, so I wasn’t relishing changing to a different player. It’s also written in Mono which doesn’t look like something I could learn very quickly.
I then noticed that Banshee has some sort of D-Bus interface where it writes things about what it it doing, such as the metadata for the currently-playing track… and so a hackish idea was formed.
Here’s a thing that listens to what Banshee is saying over D-Bus and submits the relevant “now playing” and scrobble to Last.fm. The first time you run it it asks you to authorise it and then it remembers that forever.
I’ve never looked at D-Bus before so I’m probably doing it all very wrong, but it appears to work. Look, I have scrobbles again! And after all it would not be Linux on the desktop if it didn’t require some sort of lash-up that would make Heath Robinson cry his way to the nearest Apple store to beg a Genius to install iTunes, right?
Update: Replacing the battery and retraining the receiver fixed it. I suppose it must have had enough juice to flash the LED but not transmit.
A few days ago my CurrentCost starting reading just dashes. There’s also no transmitter icon, so I think it’s not receiving anything from the transmitter. It looks like this:
I went and fished the transmitter box out of the meter closet expecting its batteries to be dead, but it still has its red LED flashing periodically, so I don’t think it’s that.
I did the thing where you hold down the button on the transmitter for 9 seconds and also hold down the V button on the display to make them pair. The display showed its “searching” screen for a while but then it went back to how it looks above.
Anyone had that happen before? It’s otherwise worked fine for 4 years or so (batteries replaced once).
All in all, around a tonne of stones and soil got bagged up and had been sitting in our front garden for a couple of months. We’ve kept four sacks for use in the back garden which left 21 sacks and around 800kg to dispose of.
I enquired at our local tipreuse and recycling centre, Space Waye, who informed me that
“waste from home improvements/renovations is classed as industrial waste and is liable for charging.”
Apparently soil from your own garden is also classed as the result of an improvement and is therefore industrial waste, the disposal of which is charged at £195 per tonne. If I were to dispose of the soil and stones at the council facility I would need to transport it there and pay in the region of £156.
Looking for alternatives, I came across HIPPOBAG. The business model is quite simple:
You pick which size of bag you require.
They post it to you (or you can buy it at a few different DIY stores).
You fill it.
You book a collection.
They come and take it away, which they aim to do within 5 working days.
They recycle over 90% of the waste they collect.
Their “MEGABAG” at 180cm long × 90cm wide × 70cm tall and with a maximum weight of 1.5 tonnes seemed the most appropriate, and cost £94.99 — a saving of £61 over the council’s offering, and no need to transport it anywhere ourselves.
The bag turned up in the post the next day, at which point I discovered a discrepancy in the instructions.
The filling instructions on the documentation attached to the bag stated that it should only be filled two thirds with soil, and levelled out. Neither the Frequently Asked Questions page nor the How To Use A Hippobag page say anything about this, and all pictures on the site show the bags filled right up, so I was completely unaware of any such restriction.
Now, I “only” had 800kg of soil but that was some 21 sacks which when placed in the bag did fill it past the top level. I don’t see how you could use the maximum capacity of 1.5t and only fill it two thirds. I was really worried that they weren’t going to carry out the collection.
With the awkward shape of the rubble sacks they weren’t packing that well into the bag. There was a lot of wasted space between them. In the interests of packing down the soil more level we decided to split open many of the sacks so the soil and stones would spread out more evenly.
I had some misgivings about this because if Hippobag decided there was too much to collect and if it were all still in sacks, at least I might have had the option of removing some of the sacks and not entirely waste my money. On the other hand it did look like it would pack down a lot further.
What we were left with was a bag about half to two thirds full of soil and stones with three or four more sacks of it plonked in the middle, no higher than the lip of the bag.
On the evening of Monday 12th I booked a collection. I was expecting to be able to choose a preferred day, but it seems the only option is “as soon as possible”, and
we aim to collect your HIPPOBAG at any time within 5 working days of your booking
So, by Monday 19th then?
I wrote in the “comments to the driver” section that I would definitely be in so they should ring the bell (they don’t need you to be at home to do a collection). I wanted to check everything was okay and ask them about the filling instructions.
The afternoon of Monday 19th came and still no collection. I filled in the contact form on their web site to enquire when it might take place.
At some point on Tuesday 20th May I looked out of our front window and the bag had gone. I hadn’t heard them make the collection and they didn’t ring the bell. It must have happened when I was out in the back garden. They shoved a collection note through our door. My comments to the driver were printed on the bottom, so they must have seen them. I still haven’t received a response to my enquiry. They did actually reply to my enquiry on the afternoon of Tuesday 20th. I’d missed that at the time this was written.
Not a big deal since they did perform the collection without issue and only a day later than expected.
Really I still think that council refuse sites should be more open to taking waste like this at no charge, or a lot cheaper than ~£156, if you can prove it is your own domestic waste.
I understand that the council has a limited budget and everyone in the borough would be paying for services that not everyone uses, but I also think there would be far fewer incidents of fly tipping — which the council have to clean up at huge expense to the tax payer.
Compared to having to transport 21 sacks of soil to Space Waye and then pay £156 to have them accept it though, using HIPPOBAG was a lot more convenient and £61 cheaper. It’s a shame about the unclear instructions and slow (so far no) response to enquiries, but we would most likely use them again.
On the morning of Saturday 12th April 2014 I visited the Kingston Upon Thames store of Metro Bank in an attempt to open a current account.
The store was open — they are open 7 days a week — but largely empty. There was a single member of staff visible, sat down at a desk with a customer.
I walked up to a deserted front desk and heard footsteps behind me. I turned to be greeted by that same member of staff who had obviously spotted I was looking a bit lost and come to greet me. He apologised that no one had greeted me, introduced himself, asked my name and what he could help me with. After explaining that I wanted to open a current account he said that someone would be with me very soon.
Within a few seconds another member of staff greeted me and asked me to come over to her desk. So far so good.
As she started to take my details I could see she was having problems with her computer. She kept saying it was so slow and made various other inaudible curses under her breath. She took my passport and said she was going to scan it, but from what I could see she merely photcopied it. Having no joy with her computer she said that she would fill in paper forms and proceeded to ask me for all of my details, writing them down on the forms. Her writing was probably neater than mine but this kind of dictation was rather tedious and to be quite honest I’d rather have done it myself.
This process took at least half an hour. I was rather disappointed as all their marketing boasts of same day quick online setup, get your bank details and debit card same day and so on.
Finally she went back to her computer, and then said, “oh dear, it’s come back saying it needs head office approval, so we won’t be able to open this right now. Would you be available to come back later today?”
“No, I’m busy for the rest of the day. To be honest I was expecting all this to be done online as I’m not really into visiting banks even if they are open 7 days a week…”
“Oh that’s alright, once it’s sorted out we should be able to post all the things to you.”
“Right.”
“This hardly ever happens. I don’t know why it’s happened. Even if I knew I wouldn’t be able to tell you. It’s rare but I have to wait for head office to approve the account.”
As she went off to sort something else out I overheard the conversation between the customer and staff member on the next table. He was telling the customer how his savings account couldn’t be opened today because it needed head office approval and it was very rare that this would happen.
I left feeling I had not achieved very much, but hopeful that it might get sorted out soon. It wasn’t a very encouraging start to my relationship with Metro Bank.
It’s now Tuesday 15th April, three days after my application was made or two working days, and I haven’t had any further communication from Metro Bank so I have no idea if my account is ever going to be opened. I don’t really have any motivation to chase them up. If I don’t hear soon then I’ll just go somewhere else.
I suppose in theory a bank branch that is open 7 days a week might be useful for technophobes who don’t use the Internet, but if the bank’s systems don’t work then all you’ve achieved is to have a large high street box full of people employed to tell you that everything is broken. Until 8pm seven days a week.
Update 2014-04-15 15:30: After contact on twitter, the Local Director of the Kingston branch called me to apologise and assure me that he is looking into the matter.
About 15 minutes later he called back to explain, roughly:
The reason the account was not approved on the day is that I’ve only been in my current address for 7 months, so none of the proofs of address would have been accepted. Under normal circumstances it is apparently possible to open an account with just a passport. If not then the head office approval or rejection should happen within 24 hours, but their systems are running a bit slowly. Someone should have called me to let me know this, but this did not happen. Apparently approval did in fact come through today – I am told someone was due to call me today with the news that my account has been opened. I should receive the card and cheque book tomorrow.
I’m glad this was so quickly resolved. I’m looking forward to using my account and hopefully everything will be smoother now.