Native Command Queueing ^
Native Command Queuing (NCQ) is an extension of the Serial ATA protocol that allows multiple requests to be sent to a drive, allowing the drive to order them in a way it considers optimal.
This is very handy for rotational media like conventional hard drives, because they have to move the head all over to do random IO, so in theory if they are allowed to optimise ordering then they may be able to do a better job of it. If the drive supports NCQ then it will advertise this fact to the operating system and Linux by default will enable it.
Queue depth ^
The maximum depth of the queue in SATA is 31 for practical purposes, and so if the drive supports NCQ then Linux will usually set the depth to 31. You can change the depth by writing a number between 1 and 31 to /sys/block/<device>/device/queue_depth. Writing 1 to the file effectively disables NCQ for that device.
NCQ and SSDs ^
So what about SSDs? They aren’t rotational media; any access is in theory the same as any other access, so no need to optimally order the commands, right?
The sad fact is, many SSDs even today have incompatibilities with SATA drivers and chipsets such that NCQ does not reliably work. There’s advice all over the place that NCQ can be disabled with no ill effect, because supposedly SSDs do not benefit from it. Some posts even go as far as to suggest that NCQ might be detrimental to performance with SSDs.
Well, let’s see what fio has to say about that.
The setup ^
- Two Intel DC s3610 1.6TB SSDs in an MD RAID-10 on Debian 8.1.
- noop IO scheduler.
- fio operating on a 4GiB test file that is on an ext4 filesystem backed by LVM.
- fio set to do a 70/30% mix of read vs write operations with 128 simultaneous IO operations in flight.
The goal of this is to simulate a busy highly parallel server load, such as you might see with a database.
The fio command line looks like this:
fio --randrepeat=1 \
--ioengine=libaio \
--direct=1 \
--gtod_reduce=1 \
--name=ncq \
--filename=test \
--bs=4k \
--iodepth=128 \
--size=4G \
--readwrite=randrw \
--rwmixread=70 |
Expected output will be something like this:
ncq: (g=0): rw=randrw, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=128
fio-2.1.11
Starting 1 process
Jobs: 1 (f=1): [m(1)] [100.0% done] [50805KB/21546KB/0KB /s] [12.8K/5386/0 iops] [eta 00m:00s]
ncq1: (groupid=0, jobs=1): err= 0: pid=11272: Sun Aug 9 06:29:33 2015
read : io=2867.6MB, bw=44949KB/s, iops=11237, runt= 65327msec
write: io=1228.5MB, bw=19256KB/s, iops=4813, runt= 65327msec
cpu : usr=4.39%, sys=25.20%, ctx=732814, majf=0, minf=6
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued : total=r=734099/w=314477/d=0, short=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs):
READ: io=2867.6MB, aggrb=44949KB/s, minb=44949KB/s, maxb=44949KB/s, mint=65327msec, maxt=65327msec
WRITE: io=1228.5MB, aggrb=19255KB/s, minb=19255KB/s, maxb=19255KB/s, mint=65327msec, maxt=65327msec
Disk stats (read/write):
dm-0: ios=732755/313937, merge=0/0, ticks=4865644/3457248, in_queue=8323636, util=99.97%, aggrios=734101/314673, aggrmerge=0/0, aggrticks=0/0, aggrin_queue=0, aggrutil=0.00%
md4: ios=734101/314673, merge=0/0, ticks=0/0, in_queue=0, util=0.00%, aggrios=364562/313849, aggrmerge=2519/1670, aggrticks=2422422/2049132, aggrin_queue=4471730, aggrutil=94.37%
sda: ios=364664/313901, merge=2526/1618, ticks=2627716/2223944, in_queue=4852092, util=94.37%
sdb: ios=364461/313797, merge=2513/1722, ticks=2217128/1874320, in_queue=4091368, util=91.68% |
The figures we’re interested in are the iops= ones, in this case 11237 and 4813 for read and write respectively.
Results ^
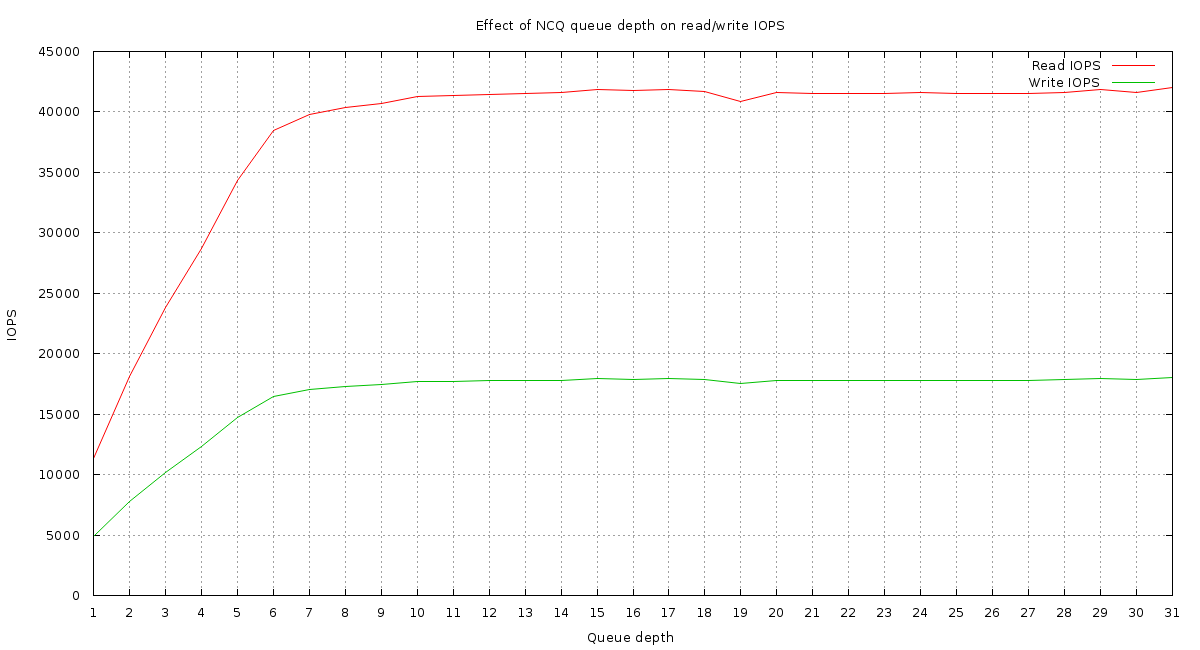
Here’s how different NCQ queue depths affected things. Click the graph image for the full size version.
Conclusion ^
On this setup anything below a queue depth of about 8 is disastrous to performance. The aberration at a queue depth of 19 is interesting. This is actually repeatable. I have no explanation for it.
Don’t believe anyone who tells you that NCQ is unimportant for SSDs unless you’ve benchmarked that and proven it to yourself. Disabling NCQ on an Intel DC s3610 appears to reduce its performance to around 25% of what it would be with even a queue depth of 8. Modern SSDs, especially enterprise ones, have a parallel architecture that allows them to get multiple things done at once. They expect NCQ to be enabled.
It’s easy to guess why 8 might be the magic number for the DC s3610:
The top of the PCB has eight NAND emplacements and Intel’s proprietary eight-channel PC29AS21CB0 controller.
The newer NVMe devices are even more aggressive with this; while the SATA spec stops at one queue with a depth of 32, NVMe specifies up to 65k queues with a depth of up to 65k each! Modern SSDs are designed with this in mind.
Interesting. Thanks for the write up and sharing.
David.
Where is the queue itself? on host side or on the drive side? or maybe on both?
Hasan,
NCQ is a part of the SATA spec. It allows drives to do re-ordering of IO so by definition those queues are inside the drive.
There will also be queues inside the host operating system and on Linux those would be managed by the IO scheduler in use, e.g. CFQ, deadline, noop, etc.
More info:
https://en.wikipedia.org/wiki/Native_Command_Queuing
How the request is divided according to the depth? If a request has a queue depth of 4, why cant it take a queue depth of 8. Is there any constrain that how a particular request is issued in ncq?