- The Discovery
- Comparing Good and Bad Copies of a Photo
- Fixing One Photo
- Fixing All the Photos?
- Which files were tampered with?
- Extract tags from known-good copies
- Stuff tags back into current versions of photos
- Profit! Or, only slight loss, I guess
- Losing some stuff…?
- Getting Tags Out of Shotwell
- Should Tags Even Be In Photos?
- Other Thoughts
The Discovery ^
Sometime in late December (2019) I noticed that when I clicked on a tag in Shotwell, the photo management software that I use, it was showing either zero or hardly any matching photos when I knew for sure that there should be many more.
(When I say “tag” in this article it’s mostly going to refer to the type of tags you generally put on an image, i.e. the tags that identify who or what is in the image, what event it is associated with, the place it was taken etc. Images can have many different kinds of tags containing all manner of metadata, but for avoidance of doubt please assume that I don’t mean any of those.)
I have Shotwell set to store the tags in the image files themselves, in the metadata. There is a standard for this called Exif. What seems to have happened is that Shotwell had removed a huge number of tags from the files themselves. At the time of discovery I had around 15,500 photos in my collection and it looked like the only way to tell what was in them would be by looking at them. Disaster.
Here follows some notes about what I found out when trying to recover from this situation, in case it si ever useful for anyone.
Shotwell still had a visible tag hierarchy, so I could for example click on the “Pets/Remy” tag, but this brought up only one photo that I took on 14 December 2019. I’ve been taking photos of Remy for years so I knew there should be many more. Here’s Remy.

Luckily, I have backups.
Comparing Good and Bad Copies of a Photo ^
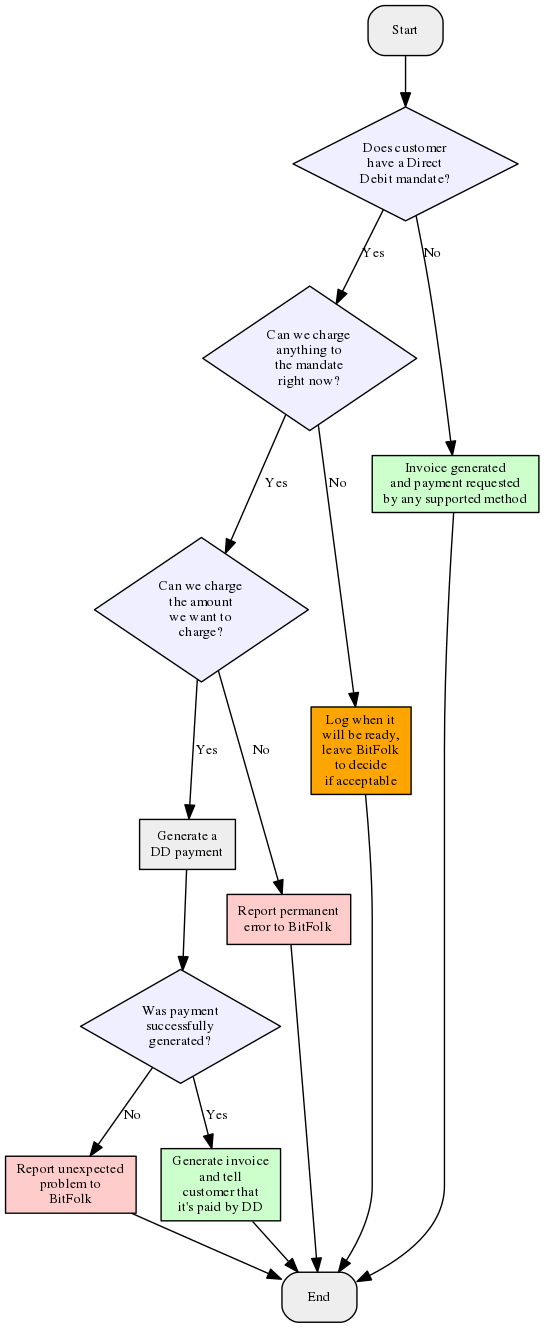
I knew this must have happened fairly recently because I’d have noticed quite quickly that photos were “missing”. I had a look for a recent photo that I knew I’d tagged with a particular thing, and then looked in the backups to see when it was last modified.
As an example I found a photo that was taken on 30 October 2019 that should have been tagged “Pets/Violet” but no longer was. It had been modified (but not by me) on 7 December 2019.
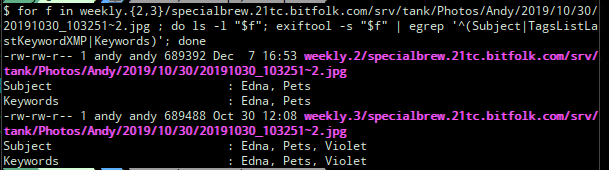
(Sorry about the text-as-images; I’m reconstructing this series of events from a Twitter thread, where things necessarily had to be posted as screenshots.)
What the above shows is that the version of the photo that existed on 30 October 2019 had the tags “Pets“, “Edna“, and “Violet” but then the version that was written on 7 December 2019 lost the “Violet” tag.
Here I used the exiftool utility to display EXIF tags from the photo files. You can do that like this:
$ exiftool -s $filename |
Using egrep I limited this to the tag keys “Subject“, “Keywords“, and “TagsListLastKeywordXMP” but this was a slight mistake: “TagsListLastKeywordXMP” was actually a typo, is totally irrelevant and should be ignored.
“Subject” and “Keywords” were always identical for any photo I examined and contained the flattened list of tags. For example, in Shotwell that photo originally had the tags:
- Pets/Edna
- Pets/Violet
It seems that Shotwell flattens that to:
- Pets
- Edna
- Violet
and then stores it in “Subject” and “Keywords“.
The tags with hierarchy are actually in the key “TagsList” like:
- Pets
- Pets/Edna
- Pets/Violet
Fixing One Photo ^
I tested stuffing the tag “Violet” back in to this file under the keys “Subject” and “Keywords“:
$ exiftool -keywords+="…" -subject+="…" $filename |
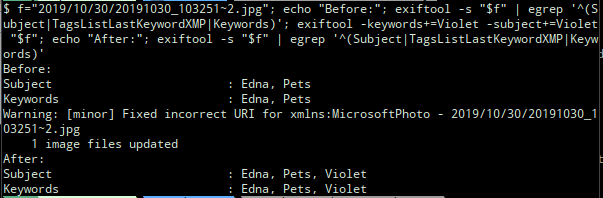
This shows that the “Violet” tag is now back in the current version of the file. After restarting Shotwell and doing a free text search for “Violet”, this photo now shows up whereas before it did not. It still did not show up when I clicked on “Pets/Violet” in the tag hierarchy however. It was then that I realised I also needed to put “Pets/Violet” into the “TagsList” key.
I ended up using a script to do this in bulk fashion, but individually I think you should be able to do this like:
$ exiftool -keywords+=Violet -subject+=Violet -TagsList+=Pets/Violet |
After restarting Shotwell I was able to click on the “Pets/Violet” tag and see this photo.
Fixing All the Photos? ^
My process to recover from this, then, was to compile a list of each file that had been modified at the suspected time of disaster, and for each:
- Read the list of tags from “Keywords“
- Read the list of tags from “Subject“
- De-duplicate them and store them as $keywords
- Read the list of tags from “TagsList” and store them as $tagslist
- Stuff $keywords back into both “Subject” and “Keywords” of the current version of the file
Gulp.
Which files were tampered with? ^
It was relatively easy to work out which files had been screwed with, because thankfully I didn’t make any other photo modifications on 7 December 2019. So any photo that got modified that day was probably a candidate.
I haven’t mentioned what actually caused this problem yet. I don’t know exactly. At 16:53 on 7 December 2019 I was importing some photos into Shotwell, and I do seem to recall it crashed at some point, either while I was doing that or shortly after.
The photos from that import and all others afterwards had retained their tags correctly, but many that existed prior to that time seemed to be missing some or all tags. I have no idea why such a crash would cause Shotwell to do that but that must have been what did it.
Running this against my backups identified 3,721 files that had been modified on 7 December 2019:
$ cd weekly.2/specialbrew.21tc.bitfolk.com/srv/tank/Photos/Andy $ find . -type f \ -newermt "2019-12-07 00:00:00" \! \ -newermt "2019-12-07 23:59:59" > ~/busted.txt |
The next thing I did was to check that each of these file paths still exist in the current photo store and in the known-good backups (weekly.3).
Extract tags from known-good copies ^
Next up, I wrote a script which:
- Goes to the known-good copies of the files
- Extracts the Subject and Keywords and deduplicates them
- Extracts the TagsList
- Writes it all into a hash
- Dumps that out as a YAML file
All scripts mentioned here script use the Perl module Image::ExifTool which is part of the exiftool package.
backup_host$ ./gather_tags.pl < ~/busted.txt > ~/tags.yaml |
tags.yaml looks a bit like this:
--- 2011/01/16/16012011163.jpg: keywords: - Hatter - Pets tagslist: - Pets - Pets/Hatter […] 2019/11/29/20191129_095218~2.jpg: keywords: - Bedfont Lakes - Feltham - London - Mandy - Pets - Places tagslist: - Pets - Pets/Mandy - Places - Places/London - Places/London/Feltham - Places/London/Feltham/Bedfont Lakes |
Stuff tags back into current versions of photos ^
After transferring tags.yaml back to my home fileserver it was time to use it to stuff the tags back into the files that had lost them.
One thing to note while doing this is that if you just add a tag, it adds it even if the same tag already exists, leading to duplicates. I thought it best to first delete the tag and then add it again so that there would only be one instance of each one.
I called that one fix_tags.pl.
$ ./fix_tags.pl tags.yaml |
Profit! Or, only slight loss, I guess ^
16m53s of runtime later, it had completed its work… 🙌 2020 will definitely be the year of Linux on the desktop¹.
¹ As long as you know how to manipulate EXIF tags from a programming language and have a functioning backup system and even then don’t mind losing some stuff
Losing some stuff…? ^
Unfortunately there were some things I couldn’t restore. It was at this point that I discovered that Shotwell does not ever put tags into video files (even though they do support EXIF tags…)
That means that the only record of the tags on a video file is in Shotwell’s own database, which I did not back up as I didn’t think I needed to.
Getting Tags Out of Shotwell ^
I am now backing that up, but should this sort of thing happen in the future I’d need to know how to manipulate the tags for videos in Shotwell’s database.
Shotwell’s database is an SQLite file that’s normally at $HOME/.local/share/shotwell/data/photo.db. I’m fairly familiar with SQLite so I had a poke around, but couldn’t immediately see how these tags were stored. I had to ask on the Shotwell mailing list.
Here’s how Shotwell does it. There’s a table called TagTable which stores the name of each tag and a comma-separated list of every photo/video which matches it:
sqlite> .schema TagTable CREATE TABLE TagTable (id INTEGER PRIMARY KEY, name TEXT UNIQUE NOT NULL, photo_id_list TEXT, time_created INTEGER); |
The photo_id_list column holds the comma-separated list. Each item in the list is of the form:
- “thumb” or “video-” depending on whether the item is a photo or a video
- 16 hex digits, zero padded, which is the ID value from the PhotosTable or VideosTable for that item
- a comma
Full example of extracting tags for the video file 2019/12/31/20191231_121604.mp4:
$ sqlite3 /home/andy/.local/share/shotwell/DATA/photo.db SQLite version 3.22.0 2018-01-22 18:45:57 Enter ".help" FOR usage hints. sqlite> SELECT id FROM VideoTable WHERE filename LIKE '%20191231%'; 553 sqlite> SELECT printf("%016x", 553); 0000000000000229 sqlite> SELECT name FROM TagTable WHERE photo_id_list LIKE '%video-0000000000000229,%'; /Places /Places/London /Places/London/Feltham /Pets /Places/London/Feltham/Bedfont Lakes /Pets/Marge /Pets/Mandy |
If that is not completely clear:
- The ID for that video file is 553
- 553 in hexadecial is 229
- Pad that to 16 digits, add “video-” at the front and “.” at the end (even the last item in the list has a comma at the end)
- Search for that string in photo_id_list
- If a row matches then the name column is a tag that is attached to that file
I don’t exactly know how I would have identified which videos got messed with, but at least I would have had both versions of the database to compare, and I now know how I would do the comparison.
Should Tags Even Be In Photos? ^
During my Twitter thread it was suggested to me that tags should not be stored in photos, but only in the photo cataloging software, where they can be backed up along with everything else.
I disagree with this for several reasons:
-
Exif exists for the purpose of storing tags like this.
-
When I move my photos from one piece of software to another I want it to be able to read the tags. I don’t want to have to input them all over again. That would be unimaginably tedious.
When I moved from F-Spot to Shotwell the fact that the tags were in the files saved me countless hours of work. It just worked on import.
If there wasn’t a dedicated importer feature then it would be so much work that really the only way to do it would be to extract the tags from the database and insert them again programmatically, which is basically admitting that to change software you need to be an expert. That really isn’t how this should work.
-
If the only copy of my tags is in the internal database of a unique piece of cataloging software, then I have to become an expert on the internal data store of that piece of software. I don’t want to have to do that.
I’ve been forced to do that here for Shotwell because of a deficiency of Shotwell in not storing video tags in the files. But if we’re only talking about photos then I could have avoided it, and could also avoid having to be an expert on every future piece of cataloging software.
-
Even if I’m not moving to a different cataloging solution, lots of software understands Exif and it’s useful to be able to query those things from other software.
I regard it very much like artist, album, author, genre etc tags in the metadata of digital music and ebooks, all of which are in the files; you would not expect to have to reconstruct these out of the database of some other bit of software every time you wanted to use them elsewhere.
It was a mistake not to backup the Shotwell database though; I thought I did not need it as I thought all tags were being stored in files, and tags were the only things I cared about. As it happened, tags were not being stored in video files and tags for video files only exist in Shotwell’s database.
Other Thoughts ^
Having backups was obviously a lifesaver here. It took me ~3 weeks to notice.
Being able to manipulate them like a regular filesystem made things a lot more convenient, so that’s a property I will want to keep in whatever future backup arrangements I have.
I might very well switch to different photo management software now, assuming I could find any that I prefer, but all software has bugs. Whatever I switch to I would have to ensure that I knew how to extract the tags from that as well, if it doesn’t store them in the files.
I don’t want to store my photos and videos “in the cloud” but it is a shortcoming of Shotwell that I can basically only use it from my desktop at home. Its database does not support multiple or remote access. I wonder if there is some web-based thing that can just read (and cache) the tags out of the files, build dynamic galleries and allow arbitrary searches on them…
Shotwell’s database schema and its use of 16 hexadecimal digits (nibbles?) means I can only store a maximum of 18,446,744,073,709,551,615 (1.844674407×10¹⁹ -1) photos or videos of dogs. Arbitrary limits suck so much.